用户不是想聊天,而是要确定条文依据
这个项目的产品核心,是把“规范查询”从关键词搜索升级为可验证的决策辅助:回答要快,但更重要的是能解释依据、覆盖条件、支持复核。
目标用户
建筑设计、规范审查、工程咨询和规范学习者。他们关心的不是 AI 是否会回答,而是回答能否对应到真实条文和适用条件。
核心任务
把“高层民用建筑防火间距如何确定”这类自然语言问题,转成可检索、可回答、可引用、可回看原文的规范查询链路。
产品风险
规范问题容错率低。漏掉条件、误读表格、不给出处,都会让用户无法信任结果,所以产品必须把证据和复核路径前置。
可信回答先从可信知识库开始
建筑规范 PDF 的难点不在“读进系统”,而在表格、条号、OCR、转引关系能不能被稳定还原。数据清洗链路决定了后面检索和回答的上限。
-
PDF Parse
MinerU 全本解析与表格裁图
对 GB50016 全本进行离线解析,生成 Markdown、content list 和表格裁图;表格最终以裁图为核对依据,而不是盲信模型输出顺序。
-
Clean
批次 patch 与 OCR 收口
按批次核对表格数值、合并单元格、单位、区间符号和常见 OCR 误识,再用 pass3 做可重复执行的清洗收口。
-
Slice
条文切片与语义打标
将清洗后的 Markdown 切成条文 JSON,并识别主表条、修正条、外部标准转引条,避免表格问题和短转引条在检索阶段被误处理。
-
Index
入库、向量索引与图谱索引
条文进入 PostgreSQL,内容向量写入 Qdrant,同时构建实体与条文关系图谱,为 BM25、Dense、KAG 三路召回提供统一数据底座。
Quick与Agentic双模式
产品提供两种检索方式:明确、单点的问题用 Quick RAG 快速定位答案;跨条件、跨条文的问题用 Agentic RAG 做规划、证据覆盖和结果校验。
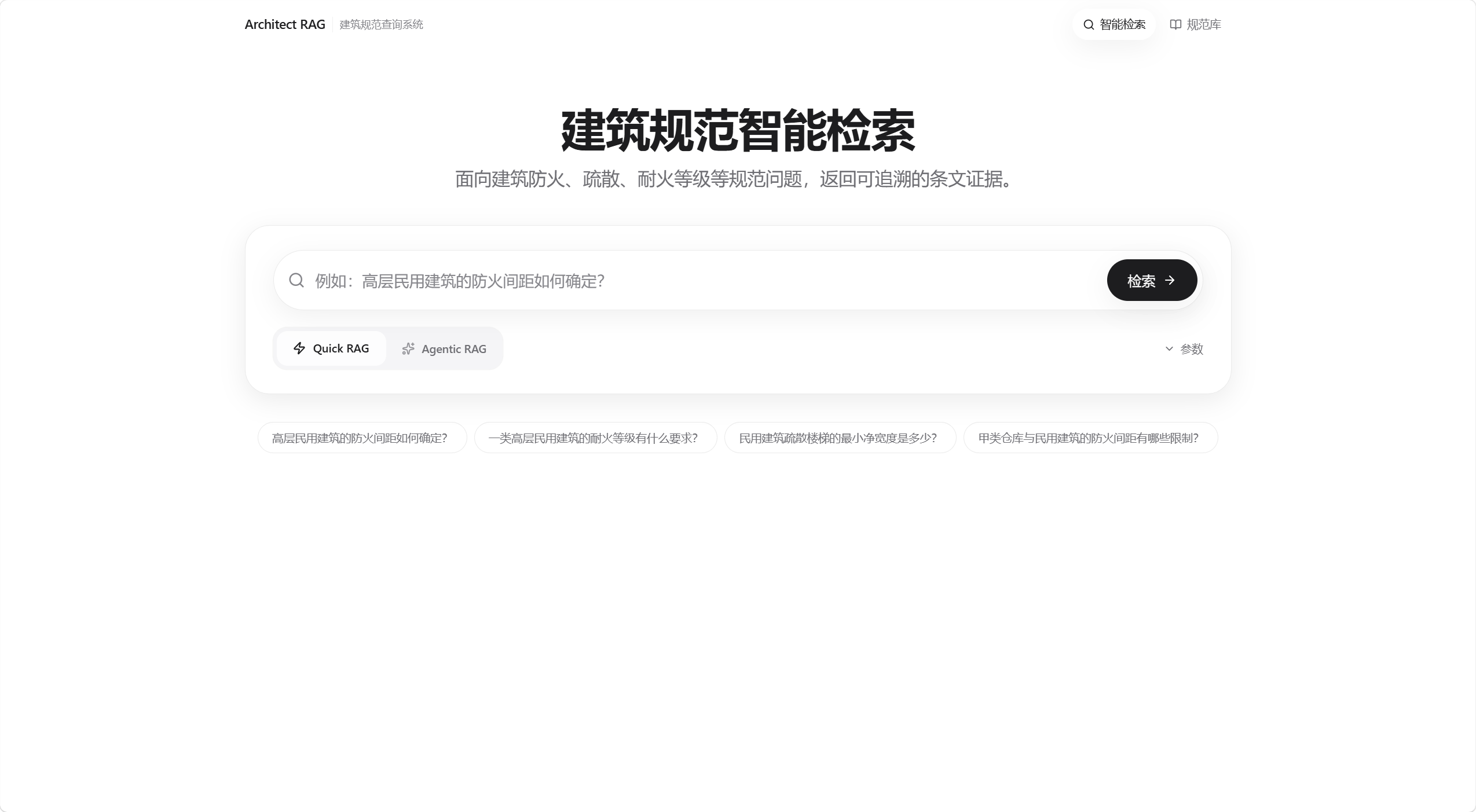
Quick RAG:低延迟直接问答
适合明确、单点的规范查询。系统通过 BM25、Dense、KAG 三路召回,经过融合与重排后快速生成答案,并保留引用依据。
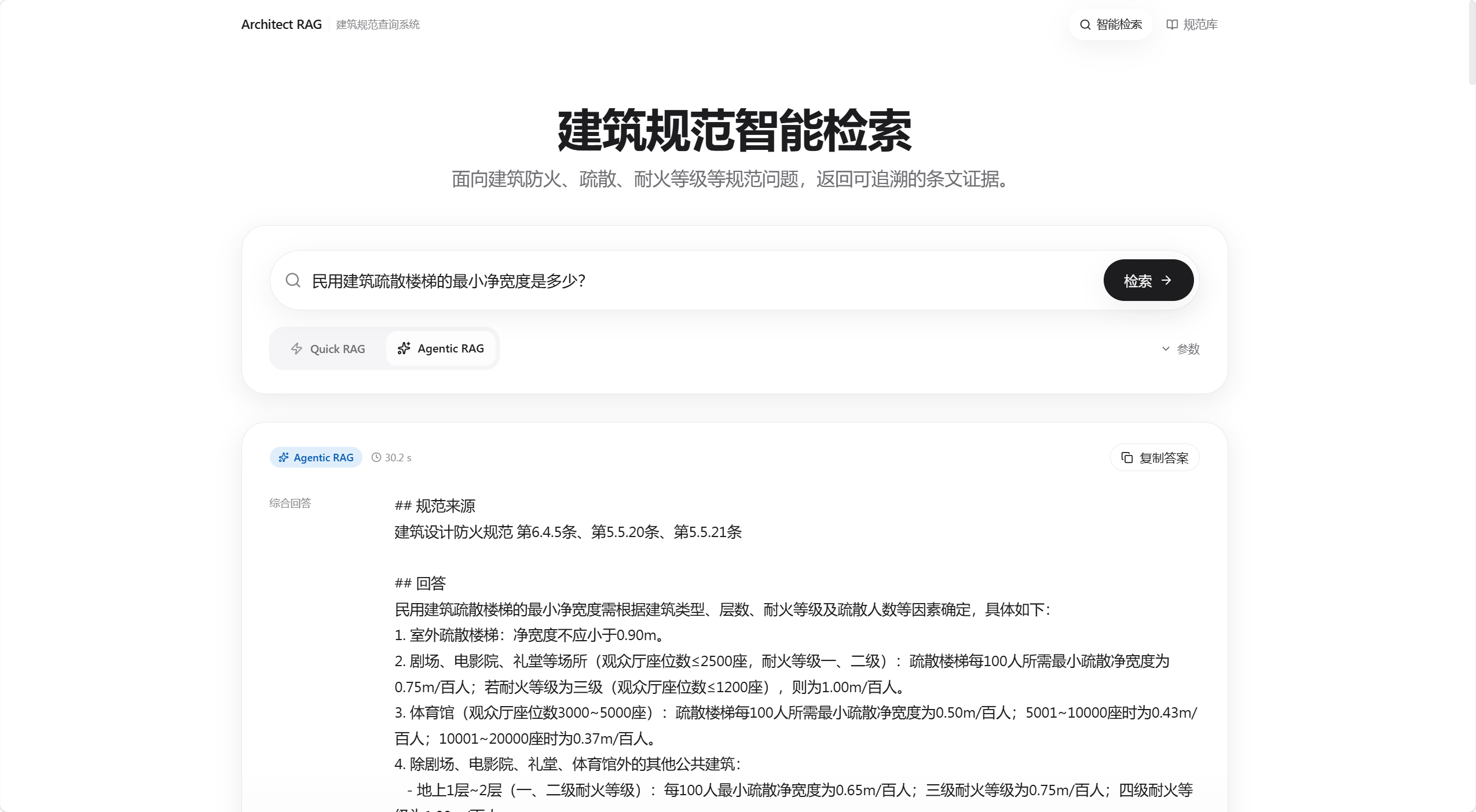
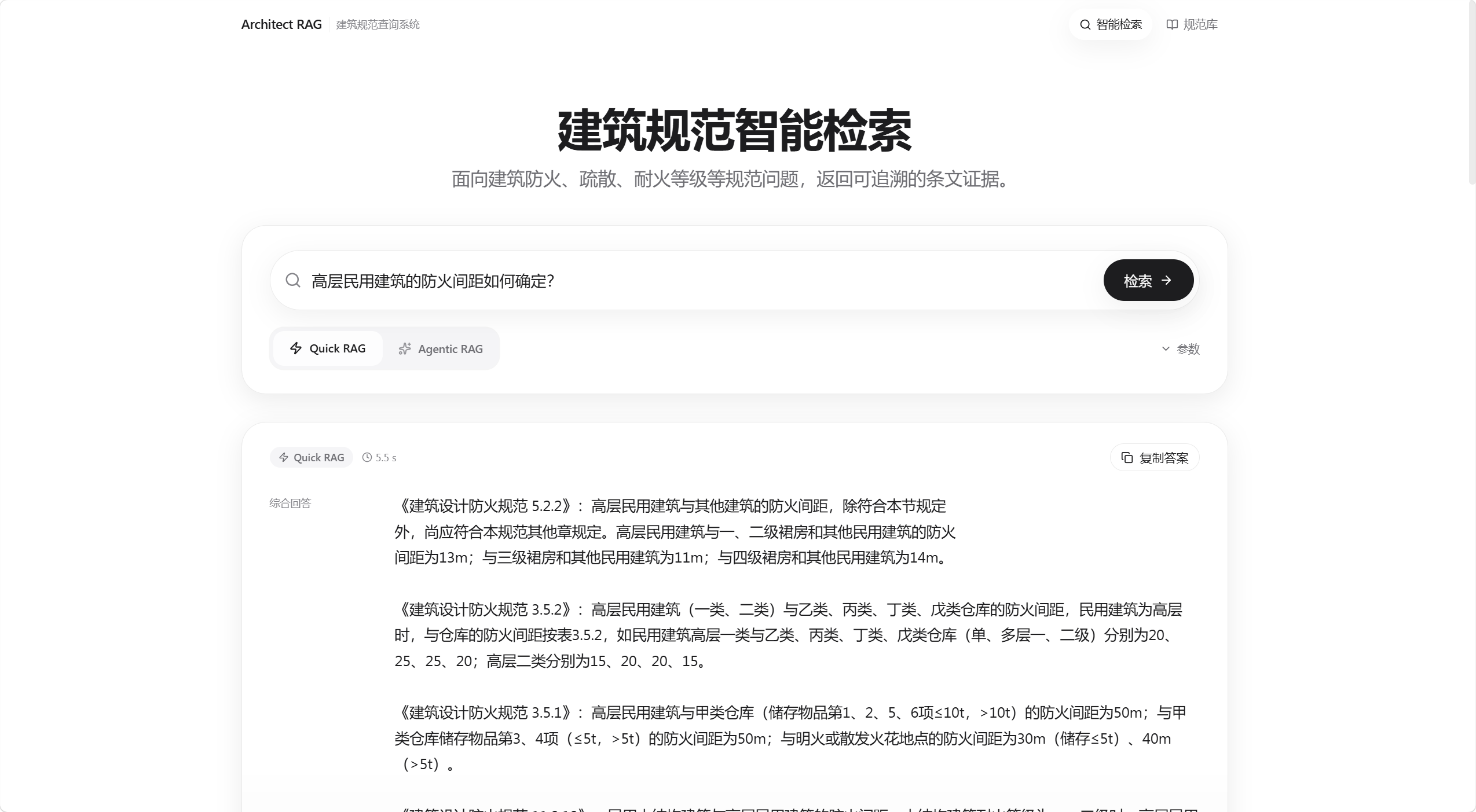
Agentic RAG:复杂问题覆盖优先
适合多条件、多条文、多子问题场景。系统会先拆解查询,再做多路检索、证据覆盖判断、缺口补检索和答案校验。
用状态事件解释复杂检索过程
Agentic RAG 的链路包含查询规划、图谱召回、证据覆盖检测与答案修复。产品通过 SSE 状态事件和 reasoning timeline 持续暴露当前阶段,让用户理解系统为何需要等待,以及结果如何被校验。
状态事件的作用
它让用户知道系统不是“卡住了”,而是在生成检索计划、查图谱、检查证据覆盖、补齐缺口或修复答案。复杂链路需要被解释,否则用户只会感知到等待时间。
-
query_plan
把自然语言问题拆成检索计划,明确子问题、实体、主题和 evidence slots。
-
graph_retrieval
检索 KAG 图谱,找到相关条文、实体和关联节点,补足关键词检索不稳定的部分。
-
evidence_coverage
检查当前证据是否覆盖问题中的关键条件,避免只答到其中一部分。
-
gap_retry
发现缺失证据后,按 missing slot 定向生成 retry query,再补检索一轮。
-
answer_repair
如果证据已经存在但最终回答漏答,只基于已有 citations 补全,不重新编造来源。
KAG补全条文关系与证据召回
建筑规范查询中,用户输入往往只覆盖部分术语。KAG 用于识别规范实体、扩展条文关系,并补充相关条件与引用条款,使召回结果从表面词匹配提升为基于规范关系的证据检索。
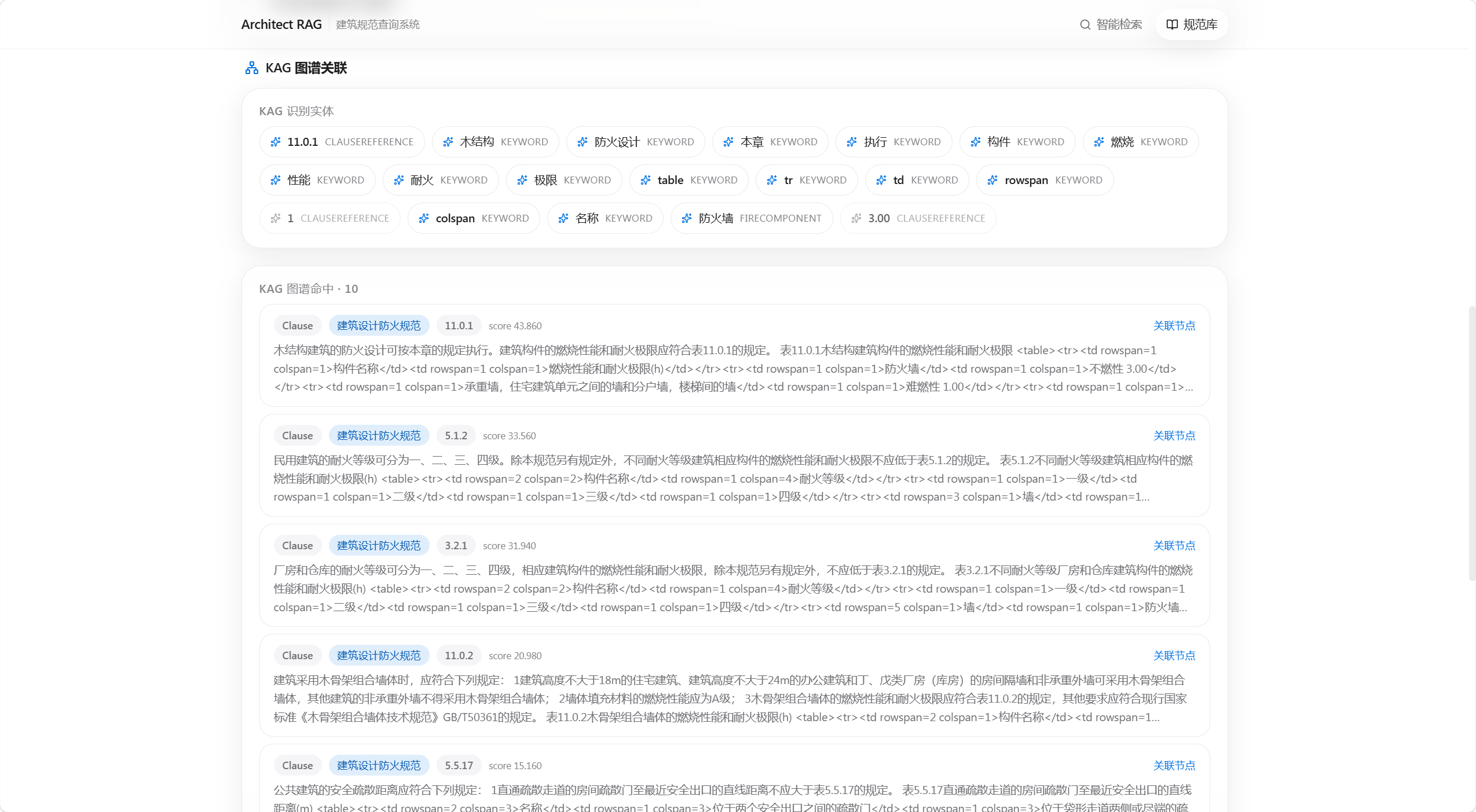
答案、引用、条文详情形成闭环
可追溯不是一句“附带引用”就结束。用户需要从答案跳到条文,再看到表格和原文上下文。
规范库:把文档整理成可浏览条文目录
规范库保留编号、规范名、状态和条文目录,让用户可以脱离问答入口直接浏览知识库结构。
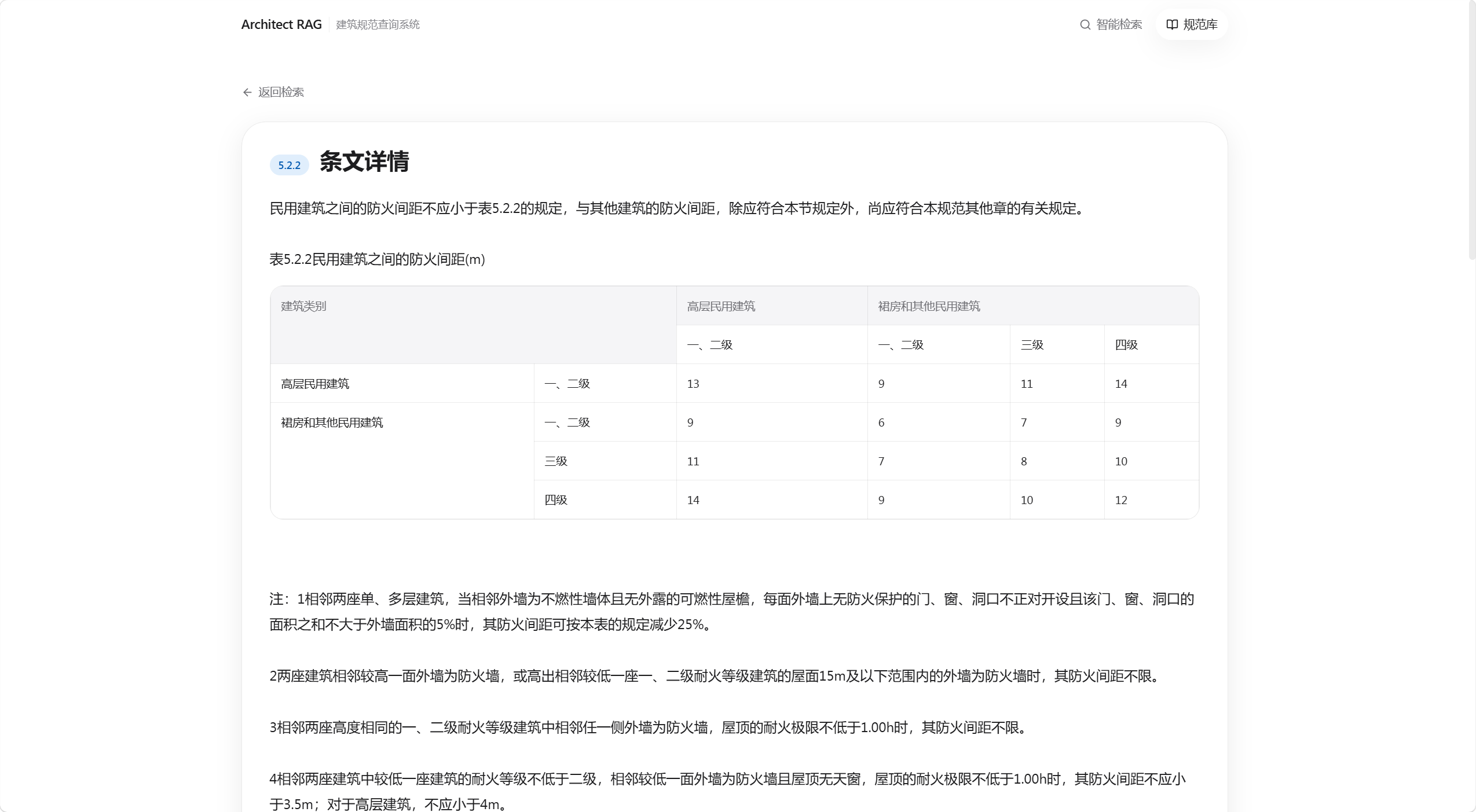
条文详情:回答背后的最终核对面
点击引用后进入条文详情,表格、正文和注释一起呈现,解决用户对 AI 答案来源的信任问题。
Direct LLM与Architect RAG同题对照评测
评测采用同一组 30 个建筑规范 query,分别输入 Direct LLM baseline 与 Architect RAG,并以金标条文、关键数值和可复核引用作为严格判分依据。评测关注的不是回答流畅度,而是必需条文命中、条件覆盖和引用可追溯性。
测试方法:同题输入,统一评分
Direct LLM 不接入规范库,只凭模型自身知识回答;Architect RAG 走检索、证据覆盖、引用回溯和答案生成。两组结果都用同一份 gold set 打分,避免主观判断。
30 个 query,easy / medium / hard 各 10 个,覆盖术语定义、表格数值、多条文组合和跨章节条件。
同一个 query 直接给 LLM,不提供检索上下文,不要求它访问规范库。
按 required clauses、关键数值、真实 citation 命中情况打分;hard query 必须覆盖全部子问题才算通过。
结果:RAG 的价值体现在“可复核的准确”
Direct LLM 能回答一部分简单题,但在多条件问题里容易漏条文、缺数值或无法给出真实引用;Architect RAG 通过证据覆盖和引用链路,把答案变成可以回到原文核对的结果。
页面背后的系统分层
架构重点是把产品体验拆成可维护的层:前端状态、服务分发、双检索管线、图谱与向量召回、重排和最终生成。
Frontend
模式切换、流式答案、引用、reasoning timeline。
FastAPI
统一接收 `/search` 与 `/search/stream` 请求。
SearchService
校验 mode,分发 Quick 或 Agentic 管线。
Retrieval
BM25、Dense、KAG 三路召回与融合。
Quality
Rerank、coverage、gap retry、answer repair。
Answer
生成答案、引用条文和可展示的状态事件。
把建筑规范查询做成可信赖的问答产品
从真实用户场景出发,覆盖规范数据处理、检索问答链路落地和结果评测,目标是让建筑规范查询不只“能回答”,还要能命中条文、解释依据并回到原文复核。
用户场景拆解
从建筑规范查询的实际痛点出发,区分单点条文查询和多条件复杂问题,设计 Quick RAG 与 Agentic RAG 两种使用路径。
规范数据清洗
处理建筑规范 Markdown、条文切片、表格裁图、主表条识别和外部标准转引,为检索、图谱和引用回溯提供可靠数据底座。
产品链路落地
串联 BM25、Dense、KAG、rerank、证据覆盖、答案生成和引用跳转,并把 Agentic RAG 的复杂检索过程转化为可展示的状态事件。
效果评测闭环
搭建 Direct LLM 与 Architect RAG 的同题评测,以必需条文、关键数值和 citation 命中作为标准,验证系统在复杂问题上的可靠性。